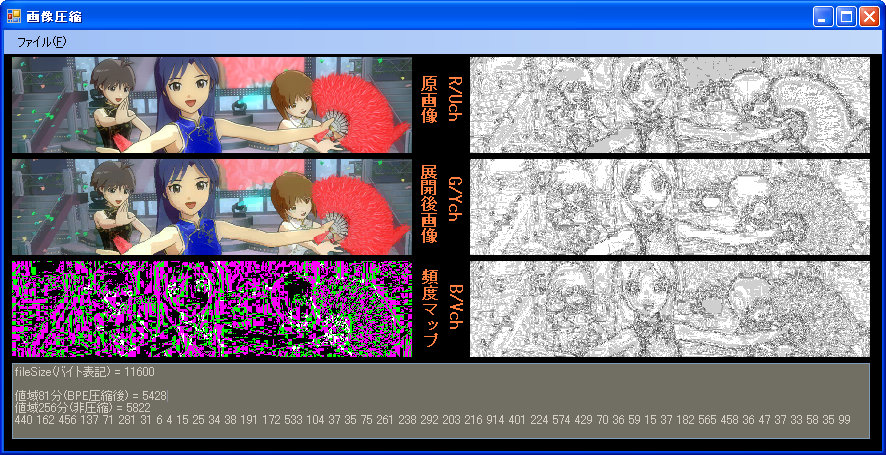

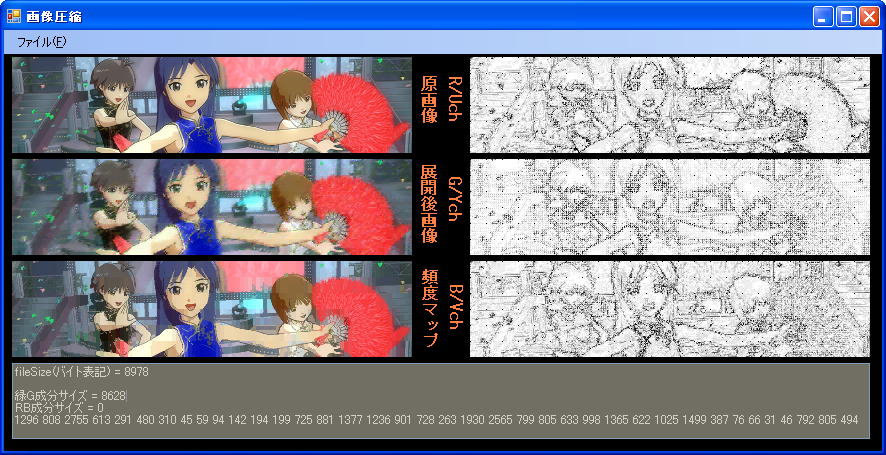
4x6MCUによる、展開が非常に高速なコーデックです。左隣継承方式を用いて、適応的に利用方式を変えることで
高効率となっています。値域81と値域256の2方式からなり、値域81の部分のみ、BPE圧縮されます。
(Rch,Gch,Bchに表示されているものは、原画像と展開画像の誤差です。) 圧縮にPenD 2.8GHzで約3秒かかるのが欠点。
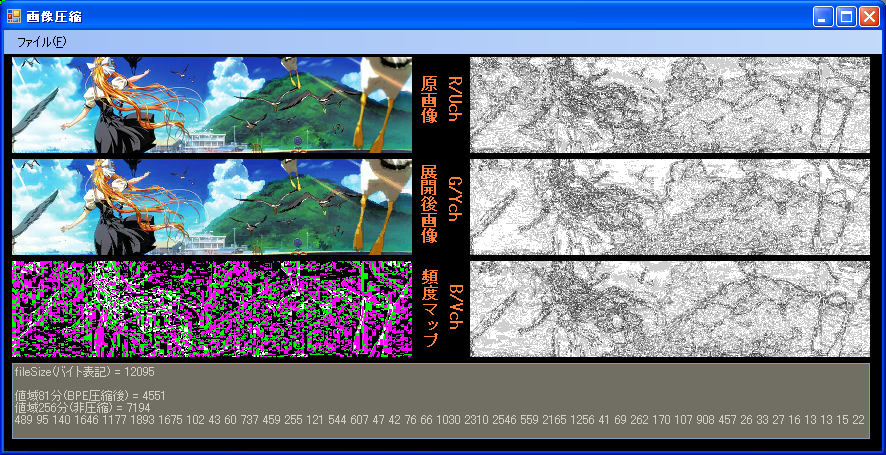
4x6MCUによる、展開が非常に高速なコーデックです。左隣継承方式を用いて、適応的に利用方式を変えることで
高効率となっています。値域81と値域256の2方式からなり、値域81の部分のみ、BPE圧縮されます。
(Rch,Gch,Bchに表示されているものは、原画像と展開画像の誤差です。)
圧縮にPenD 2.8GHzで約3秒かかるのが欠点。
2次元TW方式は、コーデックに使用するメモリが多すぎますし、24bit入出力ができません。
そこで、メモリの消費を抑えるため、2次元手抜きウェーブレットを、1次元Haarウェーブレット・または1次元手抜きウェーブレットとし、
あわせて入出力の24bit化を達成しようと目論んでいます。すぐ1ライン上を予測の参考にすることにより、1次元化による効率低下を抑えます。
1次元Haarウェーブレットは、そのままでは可逆圧縮なので、非可逆化と、なめらかなグラデを実現する予測を考えています。
a,b,c,d → a+b,a-b,c+d,c-d → a+b+c+d,a-b,a+b-c-d,c-dという最も単純な変換で、a+b-c-dから、a-b,c-dを予測し、予測誤差を量子化することに
より、グラデが劣化しないようにしようと考えています。予測の高精度化案を練っている最中です。
→やってみました、1次元ウェーブレット。全然圧縮できません。(処理が)軽くてキレイで重い(30KB超)のが1次元のようです。
非同期SRAMというモノがよく分からなくて恐縮ですが、画面全体を左から右に、上から下に転送する必要がないなら、16x400だった手抜きウェーブレットのMCUを
32x40とすることでメモリ使用量をおさえる手もあります。(MCUは大きいほど効率が良い。また極端に細長いと効率は低下する。)
非同期SRAMをバッファとして予測値もそこから読み、画面全体(96x400)をMCUにすると圧縮効率は良さそうですが、重そうなのと、次々に更新されたピクセル
の密度が高くなってゆく画面遷移が見えてしまいそうな気がする。
(2007/12/13追記)2次元TWは、天ぷら油がはねるような読み込みを(予測値を算出するために)行う仕様であり、その際MCUの外にアクセスしないよう、
ガードすることが処理の重さ・予測間違いの1つの原因です。そこで、ガードするかわりに、MCUの周囲に空き地を作ることを考えました。
まず、元画像を、8x8ブロックの左上ピクセルを取り、これを直流成分として圧縮記録します。解凍後には12x50x3=1.8KBのメモリを取ります。
MCUは、16x16ピクセルで、左・上に4ピクセル、右・下に1ピクセルの空き地をとって配列を確保します。(4+16+1)*(4+16+1)*3=1323Bになります。
直流成分は、MCUに4個、空き地に5個呼び出され、予測の参考とされます。
MCUの記録が終わったら、次(1個左)のMCUです。左の空き地に、MCUの右から4ピクセルまでを、次の予測のために残しておきます。
やっとTWでRGB888、4KB制限をクリアできそうです。
CPU時間と自分の時間に余裕があれば、周囲4平均以外の高精度予測方式もやってみます。
→やってみました。MCUが16x400から16x16になったせいか、あまり圧縮できません。(Airで18KB程度)
小さなMCUによる効率の低さを補うため、コードは複雑化する一方。すごく実装しにくそうなコーデックになってしまいました。
あと一つ、手抜きウェーブレット(TW)も、(MPEGのような)周波数領域系の圧縮ですので、原画像をぼかすとサイズが減るようです。
アイマスのサンプルでは16KBが11KBになりました。遠くから見ればキレイですが、精細感に欠けるのは残念と感じました。

|
|
|

渦巻き型予測(名称がないと不便なので、そう名づけます)は、アニメ調の画像に向いた予測方式です。
記録対象ピクセルから、渦をまくように回り(符号化完了したもの)を見て実際の色に近いピクセルを探し、
渦アドレス、G差分、R差分、B差分を記録します。
アドレスの記録ルーチンが間違ってました。修正したところ、20KB程度に膨れ上がってしまいました。
渦アドレスを記録するのはやめて、代わりに、4値を高速に値域で切り分ける方法を探しています。
(例:20 49 21 47→ 20,21 + 47,49 → 20or48)
(例:16 7 4 5→ 16 + 7,5,4 → 16or5)
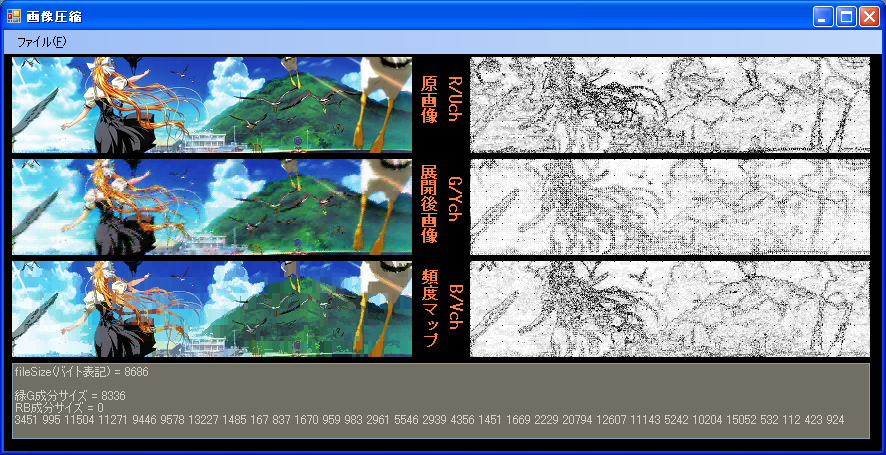
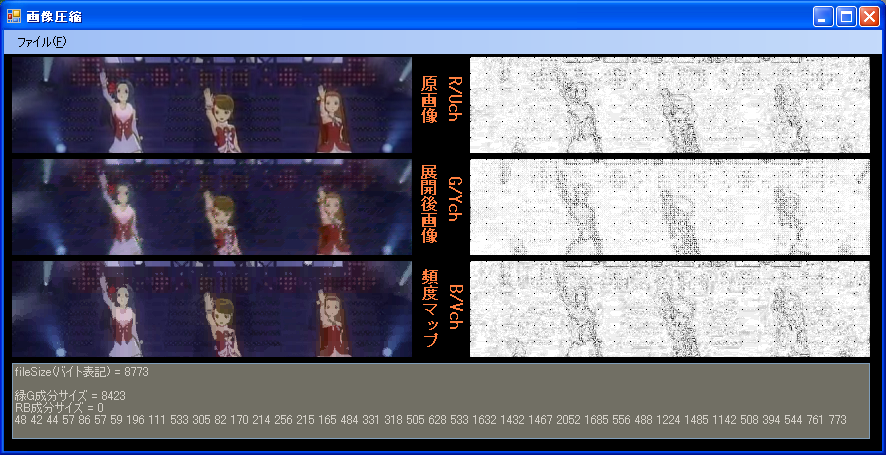
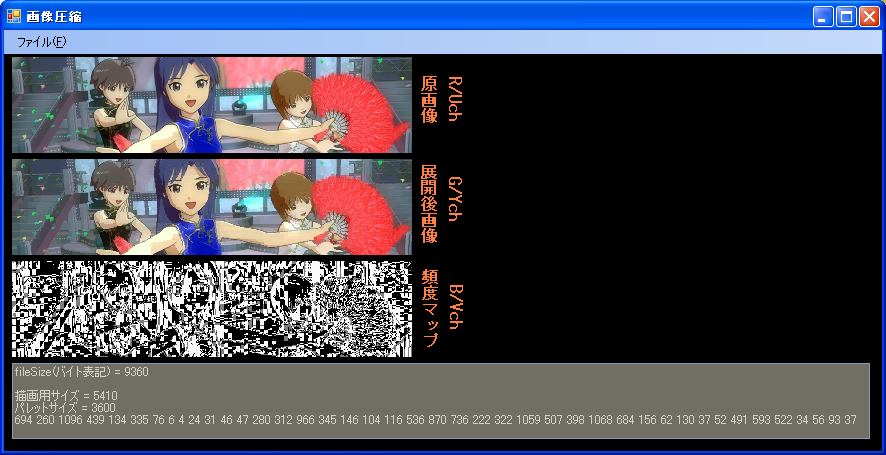
展開後画像は、こちらの方式による画像、頻度マップにあるものが、ACMになります。
表示されているファイルサイズは、ACM圧縮のファイルサイズです。
こちらの方式も名前がないと不便なので、TW(手抜きウェーブレット)圧縮とでもしておきます。
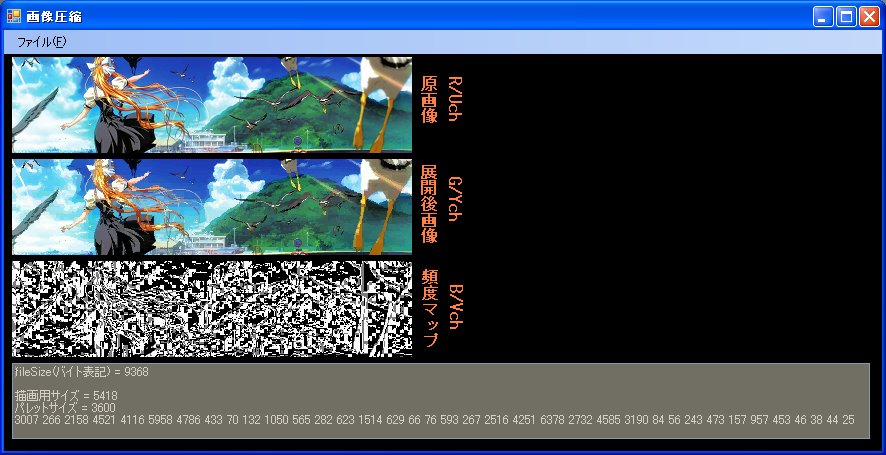
ほぼ同ビットレートでの比較ですが、見たとおり、低ビットレートでは明らかにACMが有利です。
TWを高圧縮しようとすると、量子化ステップを大きくすることになり、多くの場合、予測値をそのまま使う
ハメになります。5 X 7という場面でXを予想するとき、予測値に中間値(6)を使うと、グラデ(3456789)では
有利ですが、エッジ(5557777)では不利になります。一方、ACMはエッジの表現に適した圧縮です。
こちらのACMは、横4縦16のMCUごとに、代表色を2色(RGB666)選び、これらとその中間値の3色でMCUを塗ります。
代表色2色は、4x16=64ピクセルの組み合わせを力技で全部試します。(64x63/2 = 2016試行)
記録値は、ライン(4x1)が81通り存在するため、0~80が値域で、81~255がBPEペア符号となります。
MCUごとにライン16本、代表色記録はR1,G1,B1,R2,G2,B2の6つ(値域は0~63)、計22符号となります。
BPEがまったくかからなくても、13.55KBの帯域保障ができていることになります。
MCUを4x16としたのは、適応的にACMとTWを使い分ける場合に、TW側との親和性を高めるためです。
すごく…きれいです
以下、比較対象として同じ画像を低画質(量子化テーブルの値を大きく)で圧縮しました。
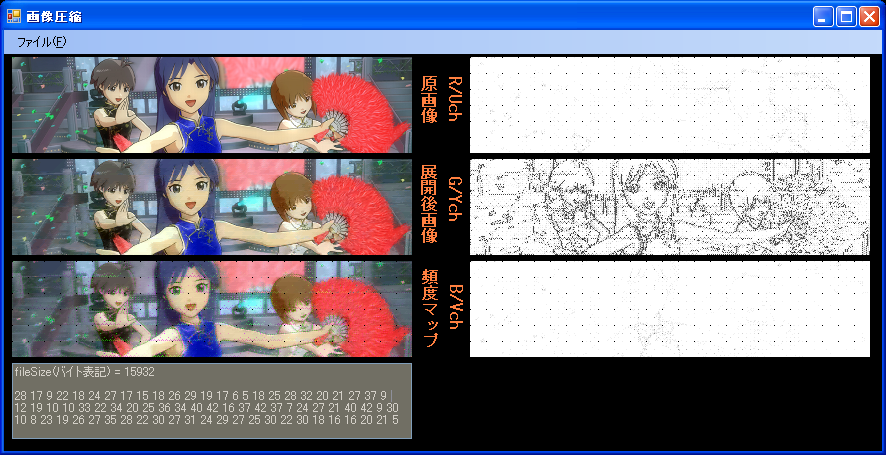
私のコーデックは、その仕様上、悪い意味でクリスピーな感じの画像を出力しがちなのですが、
そちら側のコーデックは、いい意味でソフトな感じがして、色の量子化誤差を感じない。
そのソフトな感じがどういう処理の結果発生したものなのか、わかりません。2次元Haar変換でしょうか?
空間変換を使わないでも1/14まで圧縮できるんですね
加減算によりGがRとBを引っ張るような予測をするのである意味、先っぽが潰れた平行六面体形の色空間
であると言えなくもないです。
それと、最終出力がRGB565(888ではなく)なのはシミュレートしてますか?
私のYUV実装(CinePackと同じ簡易型のもの)では、この色空間変換によるロスで、けばけばしい色使いになってしまった(ので、あきらめた)
のですが、私の実装が悪いだけなのかも知れません。
最後にもう一つ、適応型コードマッピングをするなら、マッピングに必要なパラメータも保管する必要があると思いますが、
そのパラメータ分のデータサイズは考慮していますか?
最終的にBPE圧縮にかけられるデータがどのような構造をしているのか、いまいち分かりません。特にこの部分、
またコード長が2バイト(16bit)単位であることと、MCUの最大長が48バイト(24ワード)なので
64ピクセルがどうして24ワードになるんでしょう? それが分かれば、何がそこまで高効率な符号としているか理解できると思うのですが…
高効率の秘訣が、MCUごとのダイナミックレンジに適応した記録方式であることだとしたら、私のほうでも、
16x16ピクセルごとにダイナミックレンジも記録することで値域を一定範囲に保証できるので、値域ごとに
BPEの別ストリームを作って、個別の辞書により圧縮することで高効率にできると考えます。
現在、ストリームは0~15用と0~63用の2つを用意してあり、辞書分のヘッダが増えることを理由に、ストリーム
を増やすことを躊躇してきたのですが(現在、BPE辞書ヘッダは0.8KB程度)、辞書を固定にすれば読み込み実装も簡単で、
PC側での圧縮スピードもあがるため、検討しています。
これらをシンプル化した方式で、HTML+JavaScriptに解凍ルーチンを実装してみました。
BPEストリームを1個だけにし、(G値が)近いパレットを選択する場合も、最も近い1個のみです。
テーブルの背景色で画像を表示するため、4万近くのセルを準備するので非常に重い(PenD 2.8GHzで12秒)ですが、
解凍デモを作ってみました。18.7KBになります。
(追記)オンラインで実行すると不安定なようです。上記のHTMLとdata.jsを同居させて、
ローカルで実行させるのが得策。オンラインだと、戻るにマウスを合わせてから反応まで4秒かかる…
縦サイズを32から16にしました。効率が低下し、容量が1~最大4割増えてしまうようです。
巨大な表になってしまいましたが、0から順に画素値を記録してゆく方式です。
記録してゆくにしたがって、記録済みのピクセルがほぼ一様に密度を増していきます。
横400、縦96の画像を扱うには、400x16を6段重ねることで記録します。
予測値は、すでに記録した近接する4つの画素を参考に求めます。例えば…
赤い4のピクセルの1つ上、579番のマスを記録しようとするとき、145,283,4,291が参考として使われます。
赤い4と緑の0の中間にある 16番のマスを記録しようとするとき、0,8,4,9が参考として使われます。
緑は、何も参考にせず、赤は斜め四方の4つ、青は縦横四方の4つを参考とします。
参考にしようとした部分がはみ出る場合は、反対側に廻し込む(例:y=19→y=3)安直な方法で実装しました。
番号が進むにしたがって量子化を荒くすることで、簡単に非可逆圧縮を実現できるのがメリットです。
予測がしやすく、「不意打ち」が滅多にないため、容量も削減できます。
フレームバッファはLCD駆動基板のメモリを使えるとのことですが、天ぷら油がはねるようなランダム
アクセスをするので、読み込み速度が心配。
// 仕上げ 0 1 2 3 4 5 6 7 8 910 1 2 3 4 516 初期
int quant[17] = {0,4,2,0,1,0,0,0,1,0,0,0,0,0,0,0,1};//緑用
int rbquant[17]={0,8,4,0,2,0,0,0,1,0,0,0,0,0,0,0,1};//赤青用 4で、符号が0~15になる
のように、最後の部分ほど大まかに、緑は丁寧に、また、4以上で割ると値域を0~15に収めることが出来るので、
4以上の値で割る部分をBPEの別ストリームとして、別に圧縮しています。
これらの方法は自分で発想したものですが、もしかしたらすでにこの方法を考えた人が存在するかもしれません。
if文が多い。多段パイプラインCPUなどでは、ifの予測失敗で致命的に遅くなる。
2回のif文が必要な回り込みまたはクリッピング処理が、ピクセルあたり6個もある。
(2008/06/10追記)2^nの範囲でのクリッピングならAND演算で速くできます。
本当にそのサイズで解凍できるかどうか、試していない。
32ライン毎の解凍なので、メモリを圧迫する。
解凍が追いつかない時は、フレームレートを下げて対処すると良いかもしれません。
ディスプレイが小さいと、フリッカは目立たなくなることが知られています。
220x176・2インチの液晶なら10fpsの動画でもきれいです。
RGB555、これをGRBの順番で記録。
あらかじめ符号対象の一つ左のピクセルを予想値とし、実際との差分を記録。
YUVのような色相関による圧縮を行うため、R,Bについては読み取ったGから予測を行う。
左のピクセルの色をR',G',B',とすると、Rの予測値は、R'+(G-G')となる。
Bの予測値は、B'+(G-G')になる。ただし5bit制限から、32以上、または0未満の値は
ありえないため、予測値は0~31の範囲にクリッピングされる。
また、赤・青成分の記録は、横方向の偶数番目のみとする。奇数部分は、予測値のみを使う。
予測値との差分を記録する際、値が負になった場合は32を足して正とする。
記録しようとする値は、0,1,2...と31,30...に偏るため、圧縮が容易となる。
BPE(Byte Pair Encoding)圧縮(可逆)を行う。
400x96ピクセルの場合、(GRBG)を記録した組が19200組、76800データとなる。
32以降255までの符号は全部空いているため、これらを全部ペア符号に充てることが出来る。
0~31内で符号が空いている場合でも、解凍の際不等号演算のみでペアか否か判定できるよう、
0~31はペア符号として使わない。
2ピクセルごとに以下を行い、左(GRB)、右(GRB)の順に表示すべき値を求める。
BPEの展開ルーチンで、一度に4つ分のデータ(GRBG)を一気に解凍する。BPEのバッファは、224Byte以上使われることは原理的にない。
Gの予測値は、求める対象の1個左のGチャンネルである。
Gの予測値と、BPE解凍した最初のG、この2つを足す。足し算結果が32以上のときは、32を引いて戻す。これがGの値。
Rの予測値は、左のRチャンネル + (BPE解凍した最初のG-左のGチャンネル)である。
ただしR予測値が0未満のときは0、32以上のときは31に戻す。
Rの予測値と、BPE解凍した最初のR、この2つを足す。足し算結果が32以上のときは、32を引いて戻す。これがRの値。
Bの値は、Rの値と同じ要領で解凍。
右のGは、左のGと同じ要領で解凍。
右のRは、先ほど求めた左Rの値 + (BPE解凍した4番目のG-1番目G)。これがRの値。予測値をそのまま表示に使うのが、左のRと違う点。
右のBは、先ほど求めた左Bの値 + (BPE解凍した4番目のG-1番目G)。これがBの値。
最後に、(R<<11)|(G<<6)|Bを計算し、ディスプレイに送る。G<<6なのは誤植ではなく、RGB555で記録しているため。G<<5ではない。
右のR,G,Bは、次回の使用のために値を保管しておく。
色空間をYUVにすると、特に自然画像で効果が大きく、1~2割程度の容量削減ができるが、LCDの色空間がRGB565のため、
変換の段階でロスが生じる。空のグラデーションが不自然、けばけばしい感じになるなど。また、BPEとの相性がやや悪いかもしれない。
色相関圧縮は、予測式R = R'*G/G'も試したが、引き算方式のほうが少ない容量となった。また、R,Bを最初の色として試したが、
G値先行 88,165B
R値先行 99,686B
B値先行 90,363B
(掛け算方式、3種の画像を用意して合計)となった。R'+(G-G')*2、*0.5も試したが、容量は小さくならなかった。
BPEで圧縮する際、Gデータ、Rデータ、Bデータを分けて圧縮したところ0.9%程度縮んだが、展開が面倒そうなのでやめた。
BPE圧縮をやめて静的Range Coderにし、場面に応じて頻度表を切り替えることで2割程度容量が減るのを確認している。
ただし、Range Coderにすると、標準的には2回、圧縮側で最適化しても1回の割り算は避けられない。
(2008/06/10BPEのエントロピーについて書き換え)BPE圧縮後のデータは、ハフマンやRange Coderをかける余地が少し残されている。
典型的なBPE符号のエントロピーが7.0~7.5bitなので、1割程度減らせる余地がある。
予測方式に、MPEG4で使われるDC成分予測法を用いてみたが、かえって容量が膨らんだ。
PNGのように、ラインごとに最適なフィルタを選択して圧縮すると、さらに
最大15%程度縮む。予測に使うピクセルが左方向(Sub)だけなのを、PNGでいう
Up,Averageも追加することで、縦方向の線が多い画像に効果を発揮する。(そうではない画像には効果がない)
(ただし、GBRGと組み合わせての実装が少々面倒となる。)
動画圧縮に利用する際は、記録値を、3次元誤差拡散法でディザリングしたRGB444とし、Gチャンネルの上位2bitのみを次フレームまで保管して
予測の参考とすることによりフレーム間圧縮を行うことで高圧縮となるかもしれない(未確認)。
R,B成分を一律にX座標向きに半分にするのではなく、X座標0から始まり1,8,8,8,4,8,8,8, 1,8,8,8,4,8,8,8, 1,8,…で、予測値との差分を割る
非可逆圧縮とすることで、ラインごとのフィルタ、G,RBに分離させたBPEとの組み合わせにより、13~33%(自然画像では効果が大きい)、
上のサンプルよりも圧縮できることを確認した。例えばピクセルのX座標が2のとき、B予想値 - 実際のB値が-9のとき、
8で割って、-1を上の方法で記録する。非可逆だが、見た目ほとんど遜色ない画像となった。JPEGのような人間の視覚特性(高周波に鈍感)による
圧縮が、不正確ながら再現されている。
ただし、実装は少々面倒になるし、処理速度も落ちる。
掲示板の書き込みを見て、それっぽい方法で実装してみました。
ただし時間の都合で、書き込み通りの方法ではなく、簡略化して実装しました。
> 8x8ピクセルの64点をMCUとしてYUV420間引きを行い
とありますが、私の実装は、データをYUV420には変換せず、RGB方式で、R,G,Bそれぞれの最大値最小値を求めて、それを両端2点とします。
(RGB555以上の精度は意味がないので、その場合長くする) シフト演算を除く乗算は4回必要です。
YUV変換を今回省略した理由は、ヒストグラムの両端2点を求めたという時点で、実はかなり勝ち組だからです。
赤から青へのグラデなど、YUV変換ではYに収束してくれないマニアックなグラデも、ヒストグラムがあれば、RGB3chのうちの任意の2chについて、(全部8点での符号化の場合)
0-7 1-6 2-5 3-4 4-3 5-2 6-1 7-0または0-0 1-1 2-2 3-3 4-4 5-5 6-6 7-7のいずれかに収束してくれますし、これはBPE圧縮がうまく汲み取ってくれます。という説明案を書きかけ、時間切れorz
私の実装では、8x8ピクセルごとにヒストグラムを作成し(RGBごとに64点抽出・Gは6点内挿、RBは2点内挿)、横隣の2ピクセルごとに、
左の記録値がG*4+R、右の記録値がG*4+Bという実装になっています。MCUごとにGが64個、Rが32個、Bが32個ということになります。
左はBが、右はRのデータが足りませんが、これはそれぞれ右、左から借りてきます。
RGB相関による補完も使えるので、見た感じの劣化は避けられます。
> これはヒストグラムの特徴点をうまく内挿点にマッピングできるかどうかで、画質が大きく変わってしまいます
かなり安直な方法で記録した、ずぼらな実装です。
また、圧縮方法は、G*4+R,G*4+B,G*4+R,G*4+B,G*4+R,G*4+B,…が延々と続く配列(値域は0~31、個数は400x96=38400)のみをBPE圧縮。
両端2点データ(5bit*6*600ブロック、ベクトルデータと呼んでます)は、非圧縮で実装しました。8bit配列で42KB、5bit詰め合わせで26.25KBの帯域保証が出来ています。
ベクトルデータもBPE側に同居させると、容量の少ない画像(23KB以下)では圧縮できるが、そうでない複雑な画像では、かえって邪魔になって
容量が増加するのを確認しています。
BPE圧縮はクセのある圧縮で、私の経験上、値域が256中96程度のデータを圧縮したときうまみが最も大きいアルゴリズム
ですが、今回は値域が31までなので、実際単なる5bit詰め合わせよりもあまり減っていない等、特性を生かしきれていない。
ハフマンやRange Coderの方がずっと圧縮できそうなデータかもしれません。(未確認)
また、ためしにGデータをR,Bと同様に2点内挿の4点としたところ劣化が激しかった。
また、空や人物の肌等ざわめきの少ないなだらかな部分と、境界部分や線画の線等急峻で値変化の大きい部分を
同じブロックに同居させると、処理の難易度が上がることが分かります。「混ぜるな危険」かもしれません。
混ぜないために4x4のMCUも試してみましたが、BPE圧縮の結果が2KB程度減る代わり、ベクトルデータが10KBも増えるため断念。
4x2程度の小さなブロックごとに、最大値最小値の差をあらかじめ全部求めておき、「なだらか」「急峻」部分で切り分けた変則的な形のブロックで符号化する方法も考えられます。
アイマス動画は、かなり圧縮に適する。
ためしにスクリーンショットを3枚非可逆圧縮してみたところ、12、13、14KBで圧縮することが出来た。
これなら、フレーム間圧縮を使わずに、195KB/毎秒(=1.6Mbps)まで圧縮できる。しかも動画では、圧縮側の誤差拡散が3次元で行える。
背景の細かい模様が圧縮の妨げになるのではないかと考えていたが、そうでもないようだ。問題は処理速度。20MHzで15fpsに追いつくか?
可逆圧縮は、容量が大きすぎる。(10~40KB)
非可逆圧縮では、様々な画像を実際に圧縮してみて、最も大きな画像では36KBでした。
この容量では、15fpsで平均30KBの画像を表示すると、3.6Mbpsの帯域となる。
V850ES/JG2@20MHzで計算すると、フレームレートが15fpsの場合、1ピクセルを34Hzで処理する必要がある。これは可能か?
機械語に詳しいわけではないので恐縮ですが、43MIPS@20MHzというスペックからして、理想的な状況で1ピクセル当たり74命令ということになると想像しました。
ただし自分の仕様では、RGB相関を利用するために1ピクセルあたり4回if文を使う箇所があります。。
またメモリにも詳しいわけではないので恐縮ですが、前後フレーム間の圧縮に際し、24KBのワークメモリではせいぜい2bit/ピクセルを保管するのが精一杯
ではないかと予想したのですが、何か策が有るのでしょうか。